
Ongoing - API Migration for Robot Fleet Management
Managing a high-stakes initiative: mitigating privacy and maintenance risks, aligning stakeholders with the customer experience, and sequencing a reliable rollout

This project is in development and does not represent my employer.
To test my systems design and technical skills, I strategized a migration of legacy, on-premises services to be containerized in a multi-region cloud environment with 99.999% service availability.
At the time, research on robot fleet management showed that legacy APIs at the enterprise level struggled with:
Resolutions to critical incidents. Immediate resolution was dependent on individuals, instead of systems. Long-term resolution would lead to lengthy re-designs and cripple product roadmaps.
Thorough system testing by service. The use of older languages and paradigms resulted in a monolithic application design, resulting in difficulty with changes to the business logic and points.
Service reliability and availability. Due to many services still remaining on-premises, any server outages would result in slow or failed API calls, with catastrophic consequences on the perceived reliability of the service.
Latency. With several health checks and calls across multiple regions, a single API call would have a P50 of 1 second, compared to the industry standard of 200ms or less (in other words, there should be at least a 50% probability that an API call will require 1 second or more).
Data integrity. Given the historical cost of data storage and messaging services, many services connected directly to the secondary sources of truth.
Problem
How might we increase service availability and reliability for critical customers who rely on the service as a source of truth?
(Anticipated) Outcome
Intermediate optimizations to the on-premises service: health checks, rules for failover, refactoring.
Long-term approach to meet customer needs: containerize the service and migrate to an active-active, multi-region cloud architecture; utilizing original sources of truth.
Realignment with all related applications, business stakeholders, and producers and consumers of the data for end-to-end experience.
AI Notice: this project utilized Claude for high-level architecture visualizations and API specifications.
Managing complexity
Stakeholder Management
Managing views from the perspective of different stakeholders to improve speed of decision-making and provide clarity on the impact of project risks.
Vision Alignment
Crafting project artifacts to communicating key decisions impacting customers and guiding future work.
Validating Architecture with Sources of Truth
Iterating on architecture based on findings at the code level; diving into technical documentation and schemas.
Technology Change Management
Understanding transferrable use cases for a new technology and building structures for long-term support.
Designing for future security and reliability
At a high level, the main challenges for the migration from on-prem to cloud would be:
Managing high throughput, particularly from the robot fleet. An estimated 1,440 health checks (1 per minute) would need to be made per minute per robot; one given robot may require over 10,000 calls to the core layer (business logic for fleet management).
Data streaming and latency, given the time required to retrieve and share geographical and sensor data.
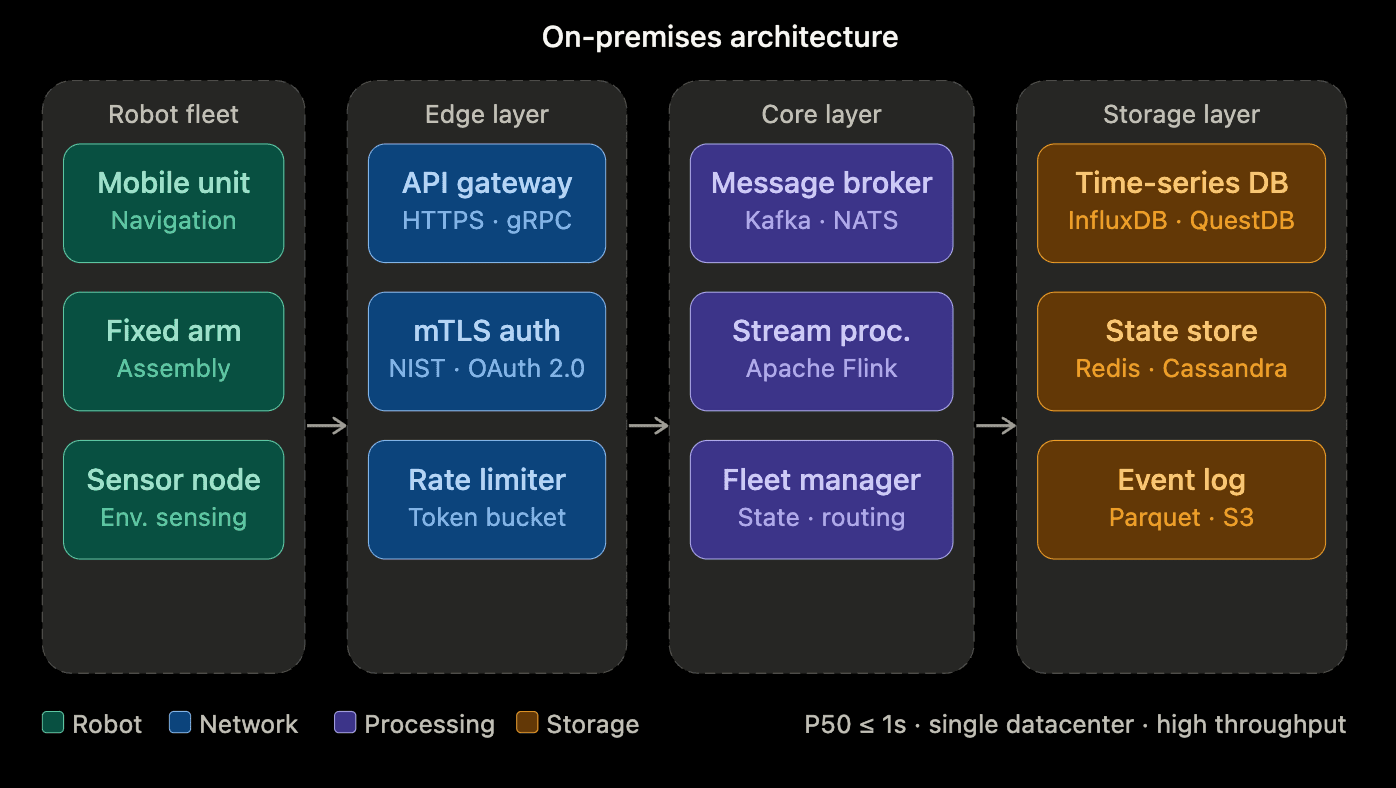
Approximation of a current-state on-premises architecture.
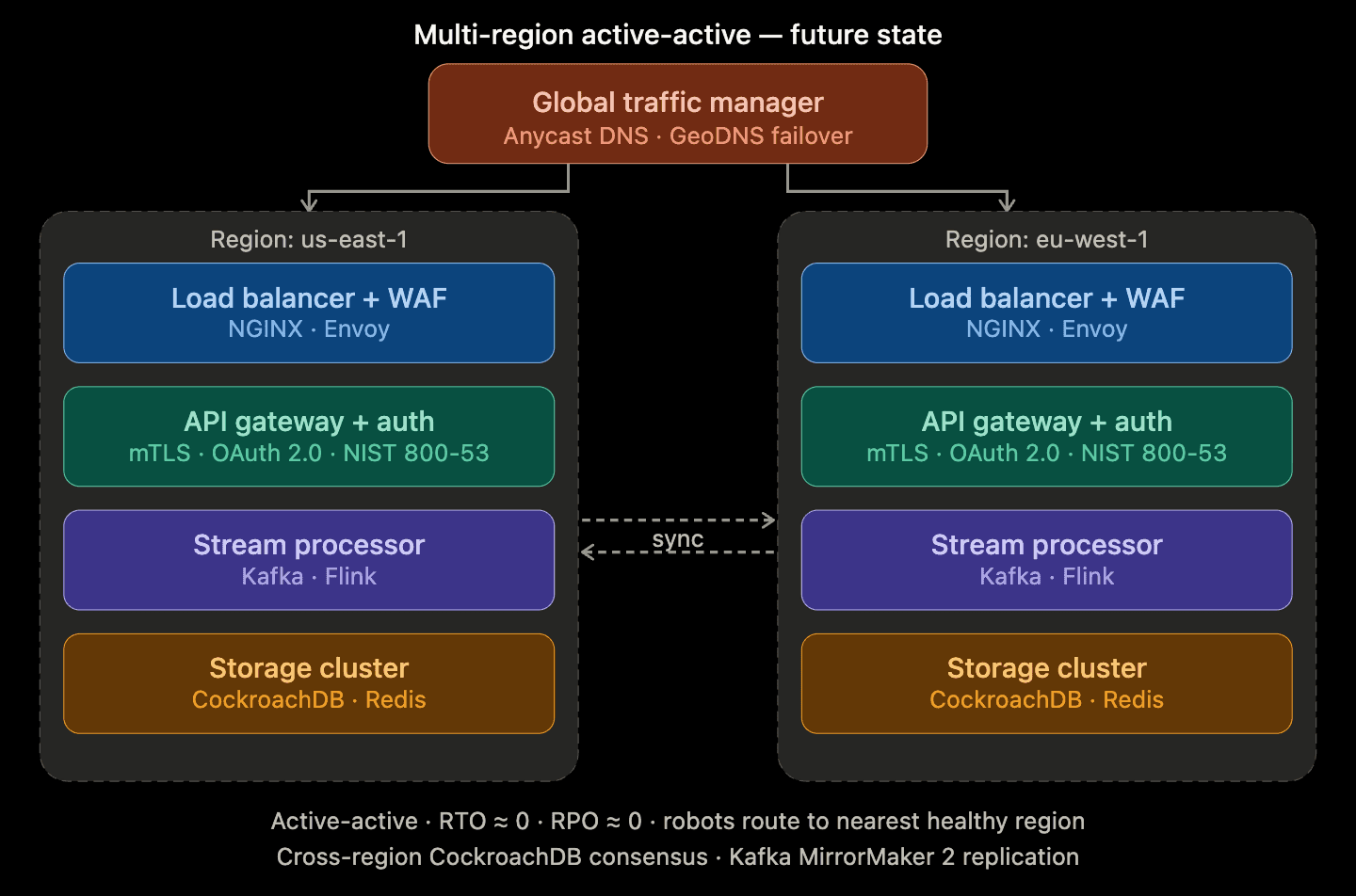
High-level cloud architecture (multi-region, active-active).
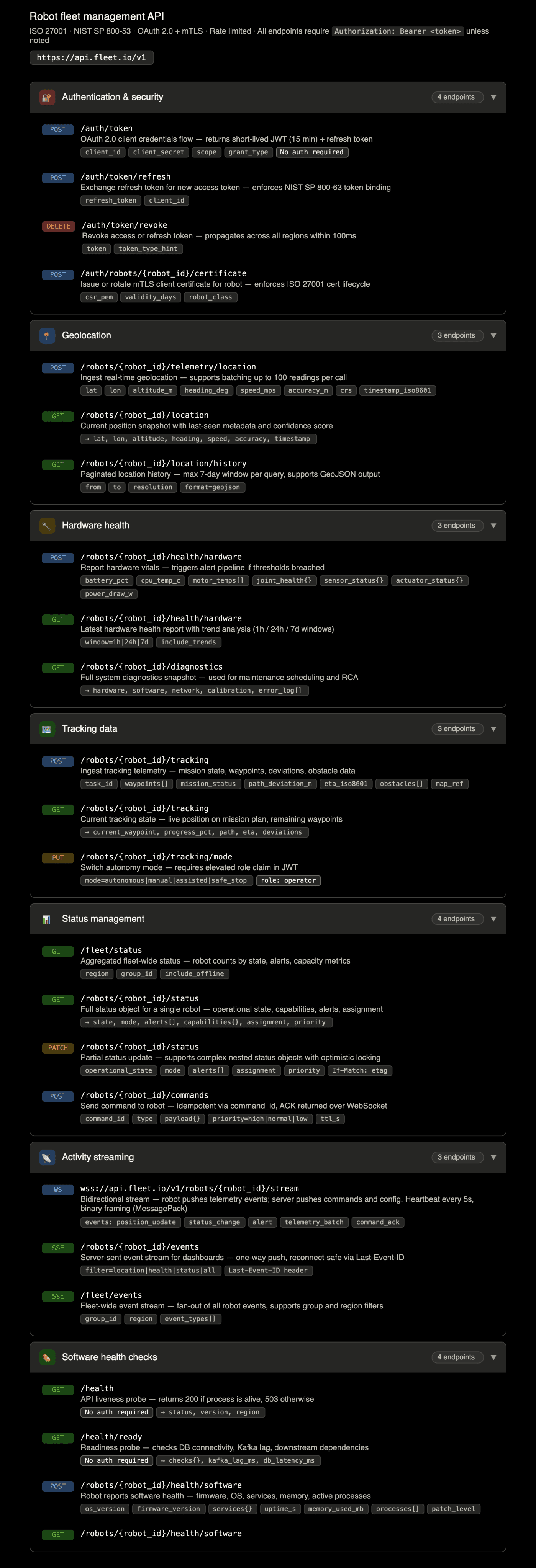
Rough API specifications for IAM, basic health checks, and event logging.
Aligning application and engineering stakeholders around feasibility and customer outcomes
Desirability, Feasibility, Viability: based on this IDEO framework, I assessed all possible solutions.
Desirability: determine end-user and customer outcomes, refer to service-level agreements (SLAs) as needed
Feasibility: remove obstacles for robust implementation and set realistic expectations based on system dependencies
Viability: achieve organizational goals, align with financial benchmarks, and account for opportunity costs
Based on the organization's principles (customer trust and reliability), I focused the team's efforts on the following outcomes:
Increasing service reliability to address the impact of server outages (current state)
Increasing service availability to empower customers with 24/7 access
Improving application infrastructure for faster troubleshooting and testing
From comparable work, I generated the following OKR.
Objective
Successfully implement a cloud architecture for a legacy on-premises system
Key Results
Reduce service downtime with up-to-date load balancers and 5 new metrics used in health monitoring systems
Achieve 99.99% availability by reducing application startup times from over 30 seconds to less than 5 seconds
Overhaul technical debt by converting the application to the newest (stable) version of its programming language and tools
Reference all source systems of data
To manage the complex system and stakeholder needs, I created communication matrices, risk logs, presentations, technical documentation and specific communications tailored to applications, database, networking/infrastructure teams.
The table below illustrates my perspective on the various stakeholder groups and priorities that needed to be addressed.
Stakeholder | Priorities | Needs |
|---|---|---|
C-Suite | Achievement of organizational goals |
|
Leadership | Achievement of department-wide goals and ability to meet customer need |
|
Application Management (Self) | Achievement of application goals and ability to meet high-priority asks |
|
IT Operations and Security Management | Managing high-level application operations and risks to the department |
|
Architecture and Data Management | Ensuring the reliability and integrity of the organization's architecture |
|
Technical Procurement and Contract Management | Managing relationships with vendors and risks to the organization's business strategy |
|
Finance | Managing financial risk to the organization |
|
Networking and Infrastructure Management | Ensuring the security and robustness of the organization's systems |
|
Upstream and Downstream Applications | Achievement of application goals and ability to meet high-priority asks |
|
Service and API Users | Ability to utilize services/APIs to achieve goals |
|
Crafting systems to support cross-functional development work
I drove collaboration and led decisions on architecture, migration planning through the following activities:
I crafted visualizations to communicate deep dives into the architecture
I evaluated data fields and business logic at the code level
I documented the current and future state schemas
I facilitated conversations across networking, IP, database, CI/CD, and application stakeholders
Updates to come.

Readings that guided my approach
Systems Design Concepts: https://www.codecademy.com/learn/ext-paths/systems-engineering-journey
Architecture
Concepts
Multi-region serverless https://aws.amazon.com/blogs/compute/building-resilient-multi-region-serverless-applications-on-aws/
Active-active https://redis.io/blog/active-active-architecture/
Disaster recovery https://aws.amazon.com/blogs/architecture/disaster-recovery-dr-architecture-on-aws-part-iv-multi-site-active-active/
Load Balancers - Multi-region
ByteByteGo Case Studies
https://blog.bytebytego.com/p/how-openai-scaled-to-800-million
https://blog.bytebytego.com/p/how-reddit-migrated-petabyte-scale
https://blog.bytebytego.com/p/how-netflix-live-streams-to-100-million
ByteByteGo Articles (high level approaches)